在数字化转型的浪潮中,企业每天都需要从网页、API、文档中获取海量数据。但传统的数据采集方式往往让人头疼:写爬虫脚本需要大量开发时间,维护成本高,遇到反爬机制就崩溃,采集回来的数据还需要人工清洗、去重、格式化。很多团队因此陷入“采集两小时,清洗一整天”的困境。数据采集智能体正是为了解决这一痛点而生的新一代工具——它不再是一个简单的爬虫程序,而是一个能自主感知、决策、执行的数据采集系统。

当前数据采集工作中的三大核心痛点
第一,技术门槛高。传统的爬虫开发需要掌握Python、Scrapy、Selenium等工具,还要应对动态加载、验证码、IP封禁等反爬策略。非技术人员只能依赖现成的采集工具,但这些工具往往缺乏灵活性。第二,数据质量差。采集回来的数据经常包含广告、导航栏、重复条目,甚至因为网页结构变化导致字段错位。第三,维护成本高。一旦目标网站改版,爬虫脚本就可能全部失效,需要重新调试。
数据采集智能体的设计思路正是从这些真实痛点出发:它要让业务人员也能轻松定义采集任务,同时让技术人员能深度定制采集逻辑,并实现自动化的数据清洗与结构化输出。
数据采集智能体的核心架构:感知-决策-执行闭环
一个成熟的数据采集智能体通常包含三个核心模块:感知层、决策层和执行层。感知层负责识别网页结构、检测反爬策略、判断数据更新频率;决策层根据预设规则或机器学习模型决定采集策略——比如是否需要使用代理IP、是否要模拟浏览器行为、是否需要分页采集;执行层则调度采集任务,并实时处理异常。
这种架构的优势在于,智能体不再是“死板”的脚本,而是能根据环境变化自我调整。例如,当遇到验证码时,智能体可以自动切换到备用采集通道,或者调用OCR服务来识别;当发现页面结构变动时,它能通过DOM相似度匹配自动修正字段映射关系。
数据采集智能体的执行流程:从任务定义到数据入库
第一步是任务定义。用户只需提供目标URL列表或搜索关键词,智能体就会自动分析页面类型(列表页、详情页、表格页等),并推荐可能的字段。对于复杂场景,用户可以通过可视化界面拖拽标记所需数据,智能体自动生成采集规则。
第二步是采集执行。智能体会根据任务优先级和网站反爬强度,自动分配采集资源。它内置了多线程调度、请求限速、Cookie管理、代理池切换等机制,确保采集过程稳定且不触发封禁。同时,智能体会实时监控采集进度,如果某个任务失败,它会自动重试并记录错误原因。
第三步是数据清洗与结构化。这是数据采集智能体区别于普通爬虫的关键。智能体内置了去重算法、格式校验器、字段映射引擎。例如,采集到的日期字段可能包含“2025-1-15”和“2025年1月15日”两种格式,智能体会自动统一为指定格式;对于空值或异常值,它可以自动填充默认值或标记为待审核。
第四步是数据输出。智能体支持将清洗后的数据直接写入数据库(MySQL、MongoDB等)、推送到API接口、或导出为Excel、CSV、JSON等格式。同时,它还会生成一份采集报告,包含采集成功率、字段覆盖率、异常记录等关键指标。
数据采集智能体的典型适用场景
在电商领域,它可以帮助品牌方监控竞品的价格、库存、评价变化,自动生成价格波动报告。在金融领域,它可以从多个财报网站、新闻平台采集数据,实现实时舆情监控。在学术研究领域,它可以批量抓取论文元数据、引用关系,辅助文献计量分析。在政府公共服务领域,它可以采集公开的政策文件、统计数据,构建数据仓库。
尤其适合那些需要“持续采集”的场景——比如每日追踪行业动态、每周更新市场数据。传统爬虫需要人工定期检查和重启,而数据采集智能体可以无人值守运行,并在数据到达时自动触发下游流程。
部署数据采集智能体后的预期效果
从实际落地案例来看,企业部署数据采集智能体后,数据采集效率普遍提升3-5倍,数据准确率从80%左右提升至95%以上。更重要的是,维护成本大幅下降:原本需要专职的爬虫工程师,现在可以由业务人员通过界面管理。同时,智能体能够自动适应网站变动,减少因改版导致的采集中断。
在数据质量方面,智能清洗模块可以过滤掉超过90%的噪声数据,字段对齐错误率降低至1%以下。这些改善直接带来了分析决策效率的提升——分析师不再需要花大量时间做数据预处理,而是可以直接使用高质量的结构化数据。
部署数据采集智能体时需要注意的关键事项
第一,合规性优先。在采集任何数据前,务必检查目标网站的robots.txt协议、用户协议和相关法律法规。智能体应内置合规性检查模块,对禁止采集的数据进行自动过滤。第二,合理设置采集频率。过高的采集频率不仅会触发反爬机制,还可能对目标服务器造成压力。建议根据网站更新频率和自身需求,设置合理的抓取间隔。第三,做好数据存储规划。采集的数据量可能快速增长,需要提前设计好数据库表结构、索引策略和备份机制。第四,建立异常监控体系。即使智能体具备自修复能力,也需要设置告警规则,当采集成功率下降或数据质量异常时及时通知运维人员。
最后,选择数据采集智能体时,建议优先考虑那些支持“低代码+可扩展”的产品。低代码让业务人员能快速上手,可扩展性则让技术人员能通过插件或API深度定制采集逻辑。一个理想的数据采集智能体应该像一位“数字员工”——它理解你的采集需求,自动处理技术细节,并交付可直接使用的数据成果。






































 智能称重系统案例
智能称重系统案例
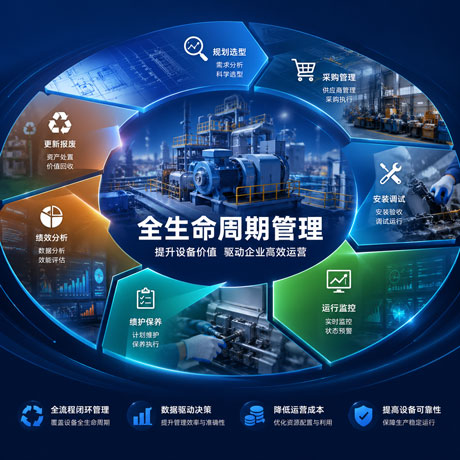 设备全生命周期管理案例
设备全生命周期管理案例
 工业数据采集与设备监控案例
工业数据采集与设备监控案例
 智能远程监控平台:彻底解决企业设备管理与安全巡护难题
智能远程监控平台:彻底解决企业设备管理与安全巡护难题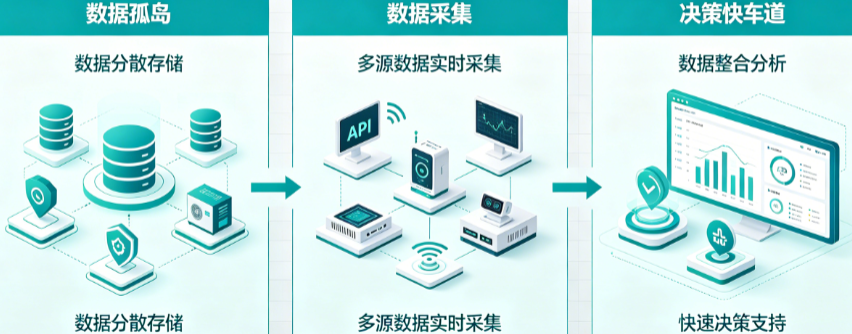 实时数据采集系统:从数据孤岛到决策快车道
实时数据采集系统:从数据孤岛到决策快车道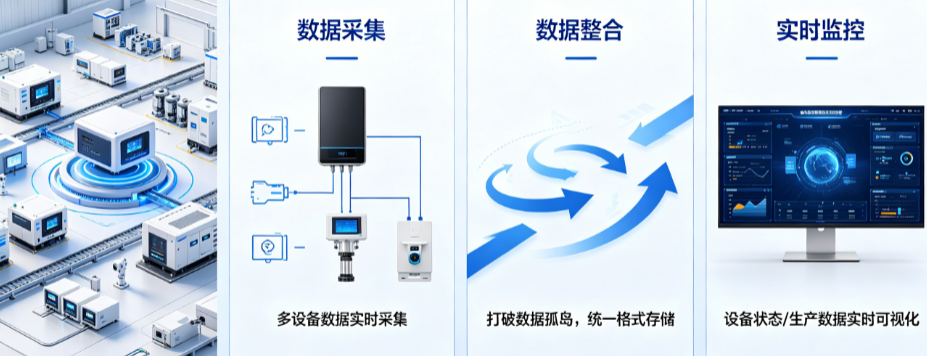 设备数据采集终端:解决工厂数据孤岛与实时监控难点的实战方案
设备数据采集终端:解决工厂数据孤岛与实时监控难点的实战方案 工厂数字化运维:从被动救火到主动预防的转型指南
工厂数字化运维:从被动救火到主动预防的转型指南